In this post we will discuss one of the common question asked by many readers of ExecuteAutomation, which is the topic name.
Its actually fairly very simple though, I just wrote 10 lines of code to achieve it (you might have even better solution than one I have)
So, here is the pseudo code
- Navigate to the URL of site you are interested in
- Get all the links of page using FindElements(By.Tag(“a”)) method
- Iterate through the page URLs and get the attributes href using GetAttribute(“href”) method
- Use Simple WebRequest and HttpWebResponse class to get the page response and status code.
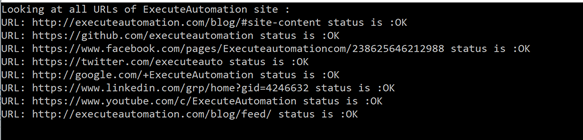
So, here is the output
Here is the source code
https://gist.github.com/executeautomation/d339d5ba35adeb46594fca1462d08957
Thanks for reading the post and watching the video!!!
Please leave your comments and let me know if there is anything I should update in this post.
Thanks,
Karthik KK



Hi Karthik,
There is no video uploaded in this post.
Thanks,
Swapna
I am out of country now, should be available soon 🙂
Thanks,
Karthik KK
Karthik, I’m running this code for my website but for some reason it fails after 2 iterations through the foreach loop. I’ve verified that it is not that link by skipping it. No matter what the 3rd link it is it fails and throws “Object Reference not set to an instance of an object. Any Ideas?
Yep.Strange .Me too facing the same problem. Every 3rd iteration fails.
Whats the alternative solution ?/
Hi,
Did you find a solution for the problem? I am facing the exact issue, after 2 iterations the loop is over. Can’t figure it out what the problem might be.
Thanks!
“Object Reference not set to an instance of an object” error message is displayed when you try to perform any action with an object which is set as “null”. In this case I don’t know what could it be (“href”, “url”, etc..). It will depend of the page that you are testing. The best way to figure out it, is debugging at the beginning of “foreach” step by step.
Maybe try it:
foreach (var url in urls){
if (!(url.Text.Contains("Email") || url.Text == "" || url.Text == null))
{
var href = url.GetAttribute("href");
if (href == null)
{
System.Console.WriteLine("Without URL");
}
else
{
//Get the url
re = (HttpWebRequest)WebRequest.Create();
try
{
var response = (HttpWebResponse)re.GetResponse();
System.Console.WriteLine($"URL: {url.GetAttribute("href")} status is :{response.StatusCode}");
}
catch (WebException e)
{
var errorResponse = (HttpWebResponse)e.Response;
System.Console.WriteLine($"URL: {url.GetAttribute("href")} status is :{errorResponse.StatusCode}");
}
}
}
}
Note: I didn’t try it, just a suggestion.
Great, Thanks for your comment !
I tried it and handle with try catch but found it only works for http. It doesn’t work for https..
🙁
HI sir Ia m getting Broken UI of extent repot please Help me Sir is there any
required softwares plz